Shared Adversarial Unlearning: Backdoor Mitigation by Unlearning Shared Adversarial Examples
Published in Thirty-seventh Conference on Neural Information Processing Systems. NeurIPS 2023., 2023
Recommended citation: Wei, Shaokui, et al. "Shared Adversarial Unlearning: Backdoor Mitigation by Unlearning Shared Adversarial Examples." Thirty-seventh Conference on Neural Information Processing Systems. NeurIPS 2023. https://arxiv.org/pdf/2307.10562.pdf
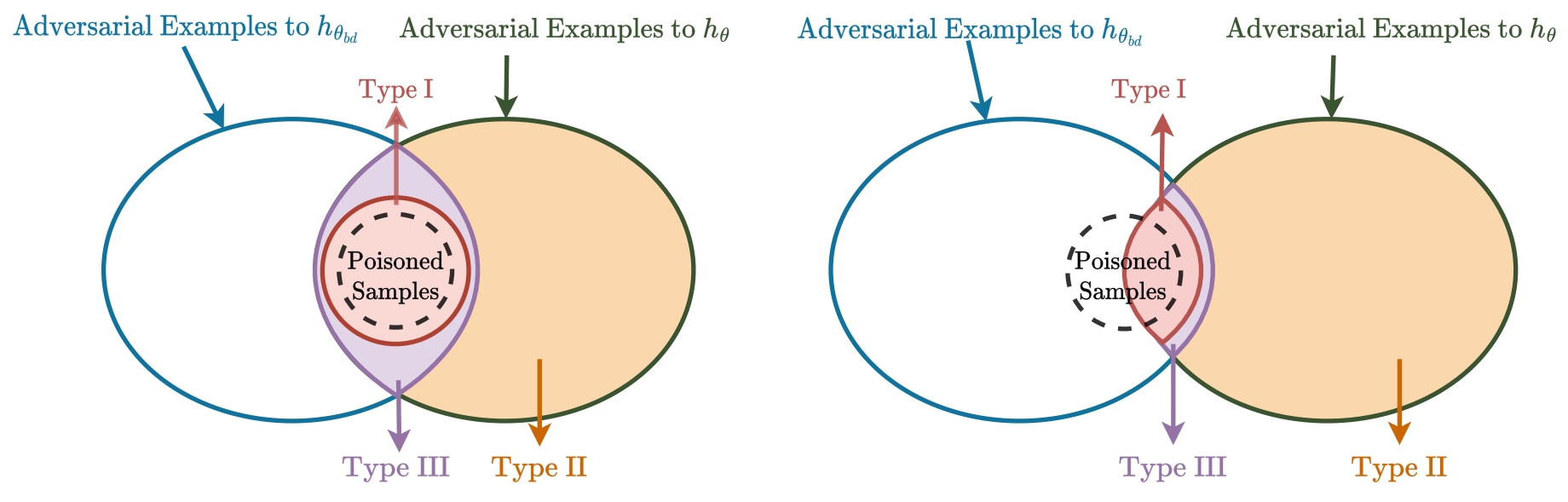
Backdoor attacks are serious security threats to machine learning models where an adversary can inject poisoned samples into the training set, causing a backdoored model which predicts poisoned samples with particular triggers to particular target classes, while behaving normally on benign samples. In this paper, we explore the task of purifying a backdoored model using a small clean dataset. By establishing the connection between backdoor risk and adversarial risk, we derive a novel upper bound for backdoor risk, which mainly captures the risk on the shared adversarial examples (SAEs) between the backdoored model and the purified model. This upper bound further suggests a novel bi-level optimization problem for mitigating backdoor using adversarial training techniques. To solve it, we propose Shared Adversarial Unlearning (SAU). Specifically, SAU first generates SAEs, and then, unlearns the generated SAEs such that they are either correctly classified by the purified model and/or differently classified by the two models, such that the backdoor effect in the backdoored model will be mitigated in the purified model. Experiments on various benchmark datasets and network architectures show that our proposed method achieves state-of-the-art performance for backdoor defense.